We are pleased to announce the UCLA synthetic data workshop. This 2-day workshop is hosted by the UCLA Department of Statistics and co-sponsored by IDRE and UCLA-Amazon Science Hub. The workshop is held at the UCLA Faculty Club.
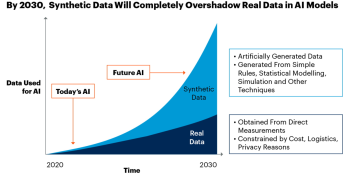
Synthetic data generation is a rapidly growing and highly disciplinary area that draws much attention from both academia and industry. For the development of algorithmic procedures for fraud detection and spam identification, as well as for the construction of AI-driven models in industries like manufacturing and supply chain management, synthetic data has become a valuable resource. The advantages of synthetic data include cost savings, increased speed, agility, increased intelligence, and cutting-edge privacy. According to the Gartner report, synthetic data will overshadow real data in training machine/deep learning models by 2030; see Figure below. Additionally, the MIT Technology Review named synthetic data as one of its top 10 game-changing innovations for 2022 earlier this year. Therefore, it is believed that synthetic data generation will be an indispensable part of the next-generation machine learning workflow.
Despite numerous successful applications of synthetic data, its scientific foundation, e.g., the tradeoff among fidelity, utility, and privacy, is still missing. Additionally, industrial standards for generating and utilizing synthetic data are not fully developed. Furthermore, the privacy law concerning about synthetic data has not been fully developed. Therefore, this workshop is to form a community of synthetic data researchers (from statistics, machine learning and mathematics), policymakers, and industrial partners, and bring them together to collaborate on the development of the theory, methodology, and algorithms needed to produce synthetic benchmark datasets and algorithms.
Updates to Speakers, Program and Poster schedules available at the workshop website!
Tentative Program
Each day runs from 9-5 up to some finetuning.
Keynote speakers (40 mins/talk):
- Aloni Cohen, UChicago Computer Science
- Xiao-Li Meng, Harvard Statistics
- Kalyan Veeramachaneni, MIT LIDS, DataCebo
- Roman Vershynin, UCI Mathematics
Panelists:
- Nikita Aggarwal, UCLA School of Law
- Ali Golshan, Gretel.ai
- Tobias Hann, MOSTLY AI
- Vamsi Krishna Potluru, J.P. Morgan AI Research
- Alexandra Wood, Harvard Berkman Klein Center
- Belinda Zeng, Amazon
Invited Session 1 (30 mins/talk): Structured Synthetic Data (Tabular and Time Series)
Invited Session 2 (30 mins/talk): Trustworthiness of Synthetic Data
- Lucas Rosenblatt, NYU Center for Responsible AI
- Jimeng Sun, UIUC Computer Science
- Steven Wu, CMU Computer Science
Invited Session 3 (30 mins/talk): Generative Models for Text/Image Data
Session Chair: Ying Nian Wu, UCLA Statistics
Invited Session 4 (30 mins/talk): Synthetic Data for Social & Medical Sciences
Session Chair: Andrés Felipe Barrientos, FSU Statistics
Poster
Travel Support
Travel support is available for junior participants (who received PhD degree after 2018), invited speakers and panel discussants. Registration fee will be reimbursed for participants that receive travel support.
Registration
Click here to register for the April 13th - 14th, 2023 UCLA synthetic data workshop.
The registration deadline is March 15th, 2023.
PLEASE NOTE: Submitting the above Google form DOES NOT guarantee a place in the workshop until the registration fee is paid. The registration fee link will become available in March and we will inform those who registered via email then.
Accommodation
If you need accommodation, nearby options include the following local hotels.
- UCLA Meyer & Renee Luskin Conference Center
- UCLA Guest House
- Palihotel Westwood Village
- Royal Palace Westwood
- W Los Angeles Westwood
Organizers
- Guang Cheng, UCLA Statistics (Chair)
- Xiaowu Dai, UCLA Statistics
- Mark Mckenna, UCLA School of Law
- Jerry Reiter, Duke Statistics
- Ying Nian Wu, UCLA Statistics
- Hongquan Xu, UCLA Statistics
Contact
For more information contact Prof. Guang Cheng.
Event Type
- Affiliate Award Fund Eligible
- NISS Sponsored
Host
Sponsor
Website
Location
Policy