 reviews a word frequency graph obtained during text mining tutorial.")
 using a poll to keep attendees involved and receive feedback as part of the session.")
Julia Silge (RStudio) is a bundle of positive energy! As instructor of the sixth tutorial in the NISS Essential Data Science for Business series, she pulled out all of the stops using polls, interactive questions, examples and more examples throughout the session. All of her slides and R code were shared with the attendees ahead of the session and it was clear that many of the participants were following the session step-by-step on their own as Julia walked through the examples online. Enthusiastic? Responsive? Yes! And Yes! Not only was there time to answer questions during the three segments of the tutorial she also took time throughout the breaks and at the end of the session to make sure that questions raised or problems encountered with the code were resolved. If you ever get a chance to sit in on a session led by Julia – you won’t be disappointed.
Comments from participants:
“She explains things clearly.”
“Her insight in to things to worry about, like sentiment lexicons could have built-in biases .... worth every penny!”
“I appreciate the great lengths Julia went to with skeletal code, and color-coded selections in her slides to help the user fill in missing details. That was above and beyond!”
The Topics
Julia Silge began by providing an overview of text mining pointing out that while these methods are becoming increasingly important, there is little or no specific “hands-on” training for those who want to implement these methods in specific analysis of the data from their everyday business efforts. From here she got down to the details explaining what is meant by “tidy” text and from this explaining and then implementing concepts from stop words to different joining methods then using these to reveal relationships of sentiment within a text.
In the second part of the tutorial Julia focused on analyzing documents. In particular she used term frequencies in relation to inverse document frequency, td-idf, as a first step towards exploring the unique characteristics of a document. She next explained how n-gram can be used in extracting additional information from a corpus to assist in network analysis, for instance, identifying words paired with the terms “he” and “she” in the text.
Julia began the final segment of the tutorial discussing how text classification can be used to train a predictive model with text data. She started with the concept of a "data budget" for predictive modeling, and how to think about training vs. testing data, as well as resampling. Julia covered both creating a statistical model for text data and feature engineering for text, focusing on how text data must be heavily preprocessed with steps like tokenization and weighting by tf-idf to be ready for modeling. She walked through how to practically implement these steps using the tidymodels framework for modeling and machine learning in R, tuning models and then evaluating them. The group then explored the output that was produced, both in terms of model performance and variable importance.
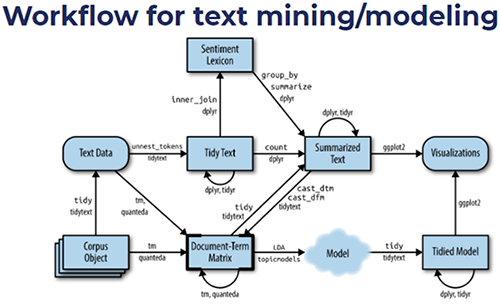
Visual overview of text mining workflow referred to by instructor Julia Silge (RStudio) during the tutorial.
For the beginner, or for the experienced, this tutorial session had something for everyone!
Access to Materials
Once again, the Essential Data Science for Business tutorials provide so many details! Models, methods, software, examples! If you were not able to attend this live session you can still access a recording of the session along with links to the slides that the three presenters used during this session. Use the Registration Option "Post Session Access" on the event webpage, pay the $35 fee, and NISS will provide you with access to all the materials for this session. Or register for the full series of ten tutorials, and NISS will provide all the links as well
What’s Up Next?
Here are the topics of the final four tutorial sessions that will presented in 2021:
- February 24, 2021: Rochelle Tractenberg (Georgetown University) "Ethical Practice of Statistics and Data Science in the Social Sciences" (see event page!)
- March 10, 2021: Jie Chen (Wells Fargo) Tim Hesterberg (Google) Juan Li (Google) "Domain Knowledge and Application Areas" (see event page!)
- March 24, 2021: Sam Woolford (Bentley University) "Non-Analytic Skills for Analytic Consulting Success" (see event page!)
- April/May (TBA), 2021: Victor Lo & Dessislava Pachamanova, "Prescriptive Analytics and Optimization" Information for registering and attending these sessions will be posted on the NISS website soon!